TL;DR
- Logging is a feature of a system
- Primary consumer of logs are machines
- Use events in logs to verify a running system
- There are benefits to using Binary encoding
Logging can be an effective way of gathering data from a system and observing its runtime behaviour. In my experience most of application logging is ad-hoc text, which greatly diminishes the potential value of logging. Most systems tend to start off with very little logging or no logging, as the system grows and problems arise developers add additional logging, which leads to megabytes/gigabytes of similar looking text, what make things worse it often not clear what information should be logged, developers often log debug/trace level diagnostic information in development but turned off in production, which makes it very difficult to extract meaningful information to troubleshoot a problem in production, as it may be missing crucial information.
Logging is a feature
There is often emphasis on designing a system for maintanability and testability, I argue that designing a system for observability is even more important as we shall see observable systems are easier to test, debug and often can help diagnose even them most crippling problems. Observable software is software which allows you to answer question about itself by simply observing facts and events emitted by the software, however this only happens by purposefully building this feature in the software itself.
"Engineers must be empowered to take the extra time to build for debuggability — we must be secure in the knowledge that this pays later dividends!" — Bryan Cantrill
Another property of Observable/debuggable software is we should be able to understand the software by observing the fact and events reported by it, In my experience understanding a complex system by observation is only possible if the facts and events have to have semantically rich information with attached context. It can be used as a way to better understand system performance and behavior, even during the what can be perceived as “normal” operation of a system. Events, tracing, exception tracking are all a derivative of the log.
Seperate information from representation
To add some form of “Observability", programmers usually log events as shown below
:::java hl_lines="2 3"
if (logger.isInfoEnabled()) {
logger.info("received price for symbol {} for date: {} with value {}",
price.symbol(), price.getDate(), price.value());
}
The logging shown above is very common, the current defacto logging API in Java atleast are centered around formatted strings, in doing so we are conflating the information and the representation. Text based logging using formatted strings are popular, main reason for this the assumption that humans are the first level consumers of the logs, however when analysing logs we usually interested in a subset of information, generally tools like grep or custom ad hoc scripts are used to extract information of interested, however this approach doesnt scale for larger applications. The other issue with formatted string based logging is that it has conflated two concerns, recording information and how it is represented, in doing so the calling code has to know how to representing the information, mixing these two concerns severely affects the flexibility and using string usually has serious impact on performance. My opinion is domain events should be represent as structured data with types.

Primary consumer of logs are programs
"Logging is the process of recording application actions and state to a secondary interface."
— Colin Eberhart
The consumer who sees this interface, the support guy/girl looking at the application log, does not have access to the application's primary interface. This means that what is detailed in this log should be driven by needs of the consumer of this interface; it is often the main source of information when diagnosing a problem. However most logs generated by popular logging frameworks are hard to read and parse, they usually contain millions of lines repeated information while key data maybe missing. There many tools and software vendors cropping up to help make sense of these large log files, While log pipelines can help to some extent their value is limited if the producer is of logs is producing data which is low quality. The root cause is how logs are produced at the source.
This may be a more contentious point, but my opinion is logs should be optimized for machines to read first. What I mean by this is, what is recorded in the logs should be sematically rich messages, which is later read by simple tools to extract information which can then be consumed by humans.
When logs are optimized for consumption by other programs, it has the benefit of many interesting side effects. It can be either to diagnose bugs or gather stats or verify the correctness of a running application, with good tooling around information in the logs can be sued to understand and improved software, not just used when a user reports a bugs or an outage has occured.

Automatic runtime and offline verification
All the data gathered via logging is useless if nobody reacts to it, one important consequence of writing logs for machines to read is it makes to possible to write programs to do Runtime Verification . Runtime verificaiton is using data from observed events from a running system to verify key invariants of a system are not violated. Having sematically rich data recorded by a running systems means we can write monitoring programs which run as a seperate process, that can verify system specifications while the system is running, this can be in production without any additional overhead on the running system.
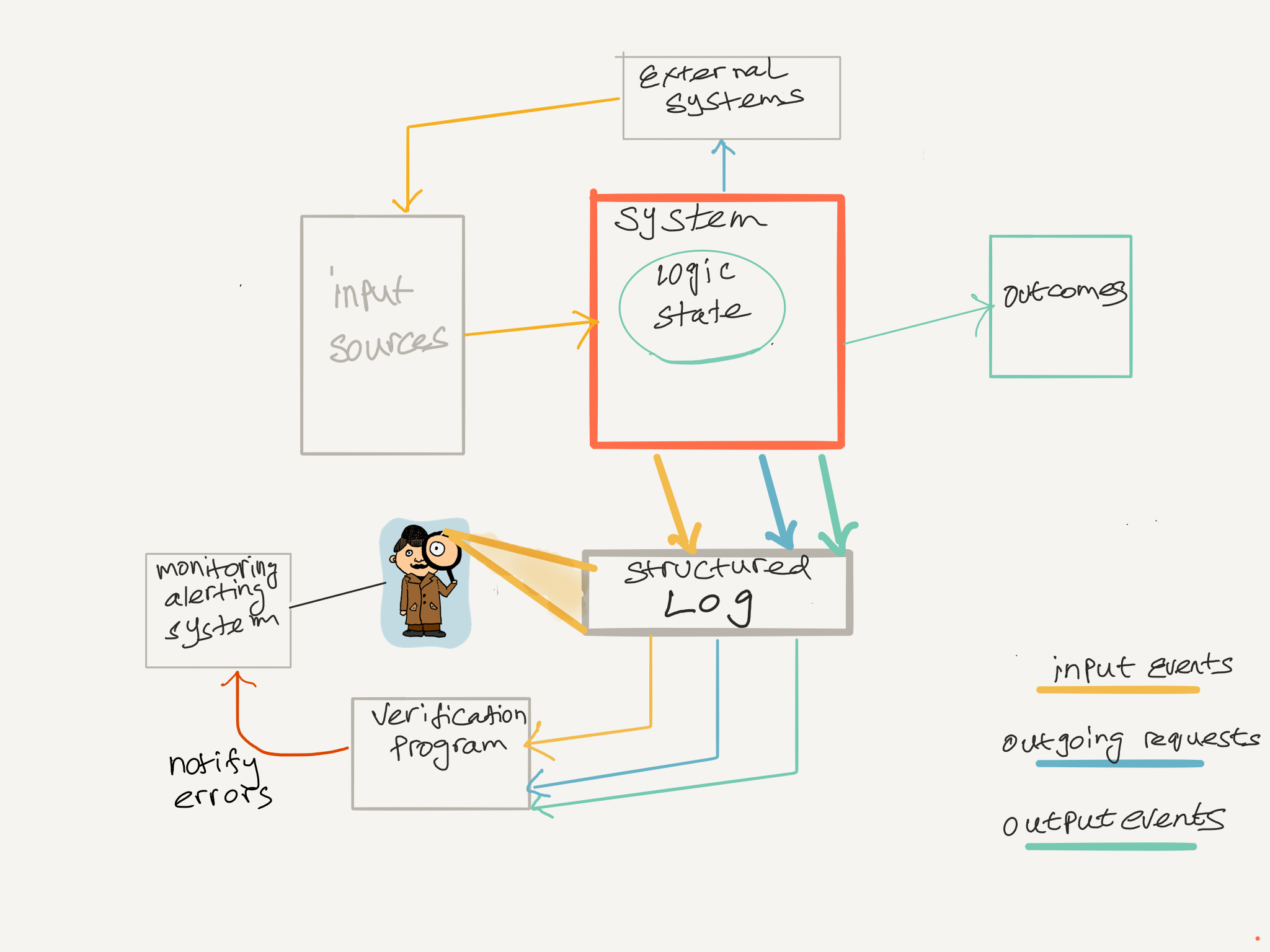
Although there is additional work for the developer to writing verification programs, the cost of writing the tool is minimal in comparision to letting bugs creep into production software, i have used this technique recently to improve the quality of a trading system . Machine readable logs with semantically rich domain events enable Runtime verification (RV) in my opinion is a very lightweight method aimed at verifying that a specific execution of a system satisfies or violates a given critical property. This type of monitoring ensures testers are notified of all specification violations, even if they are not easily noticable by testers (such as short transient violations). Used events recorded in logs can used in the assertion of temporal logic, where by the verification program can also verify properties dependent on time, (where a system can only in a particular state for a certain time period). In deployed systems, monitors can be used as a fault detector to trigger recovery mechanisms such as safety shutdowns or automatically turn off certian software feature if a fault is detected.

Efficient logging
Logging isnt free, multiple gigabytes per day are commonplace now, text based logs are simple flat files, their size comes from the sheer volume of repetive strings and entries, not from being rich data types. Although disk space is cheap now, it not just log file size not only consumes disk space during logging, there is a lot of overhead for applications to continually wirte text to disk, it also causes processing overhead when importing, analysing, and for consumer programs. Machines dont read text, they read binary One important feature of a logging library should be to minimise the overhead of logging business events, in my experience working with electronic trading system, it common for system to received several 100's of events per millisecond traditional string based logger or using text based encoding will be extremenly inefficient cause enormous overhead. Attention needs to paid to the encoding used by the logger.
Encoding
A popular choice tends to be JSON as the argument is it readable by humans and machines, however JSON is a text based encoding without any type information, and is inefficient as it can be orders of magnitude slower than a binary encoding. Having profiled a system, text based encoding used by a logging library was the biggest consumer of CPU and memory in a business application. Binary encoding is not only more efficient to encode and decode but are also compact, less memory bandwith is used, which results in lower latency. In my experience any application or service that processes a significant amounts of events, should prefer a binary encoded format for logging. Ideally use a well documented binary encoding such as SBE or FlatBuffers and build tools to debug and understand.
Errors and Counters
Errors
Unexpected errors are logged using a similar API, the stack trace provided by the exception is converted to strings, and recorded, often the same exception occurs repeatedly and is logged over and over again. While reading through some of the Aeron source code, I noticed an interesting approach to recording exceptions. The approach taken there is to log distinct errors only with a count of the number of time the errors has occured, in addition the time of first and last observation is also recorded. This means that when the same error is experienced many times only the count and latest observation timestamp is updated, this approach is not only very efficient but also very much easier to read without loss of any information.
Counters
In many cases we may have just keep a count of significant events observed in the system, for example there maybe an internal cache used in the system but we may need to monitor the number of cache misses. Rather than logging each cache miss, we could simply have a counter which is incremented each time a cache miss has occured.